Architecture of the VISION supercomputer
The VISION supercomputer is technically best described as an 3 scalable unit (SU) NVIDIA SuperPOD(opens in new window), and it is based on an NVIDIA Reference Architecture(opens in new window).
In the simplest terms, the 3 SU SuperPOD reference architecture is a carefully designed combination of multiple high performance computing components:
- 95 DGX systems (compute nodes)
- 2 InfiniBand networks (one for compute and one for storage)
- 2 Ethernet networks
- Management nodes
- 8PB Fast scratch, parallel filesystem compute storage
- 1PB NFS storage
Although the SuperPOD is an exceptionally powerful system, by itself, the reference architecture is not sufficient to meet the needs and security requirements of Texas A&M University System researchers and users. Because of this, a number of additional features and configurations have been implemented (and will continue to be developed) to make the VISION supercomputer an effective member of the fleet of supercomputers within the Texas A&M University System. Below is a block diagram of the key components.
Detailed hardware specifications for VISION are also available.
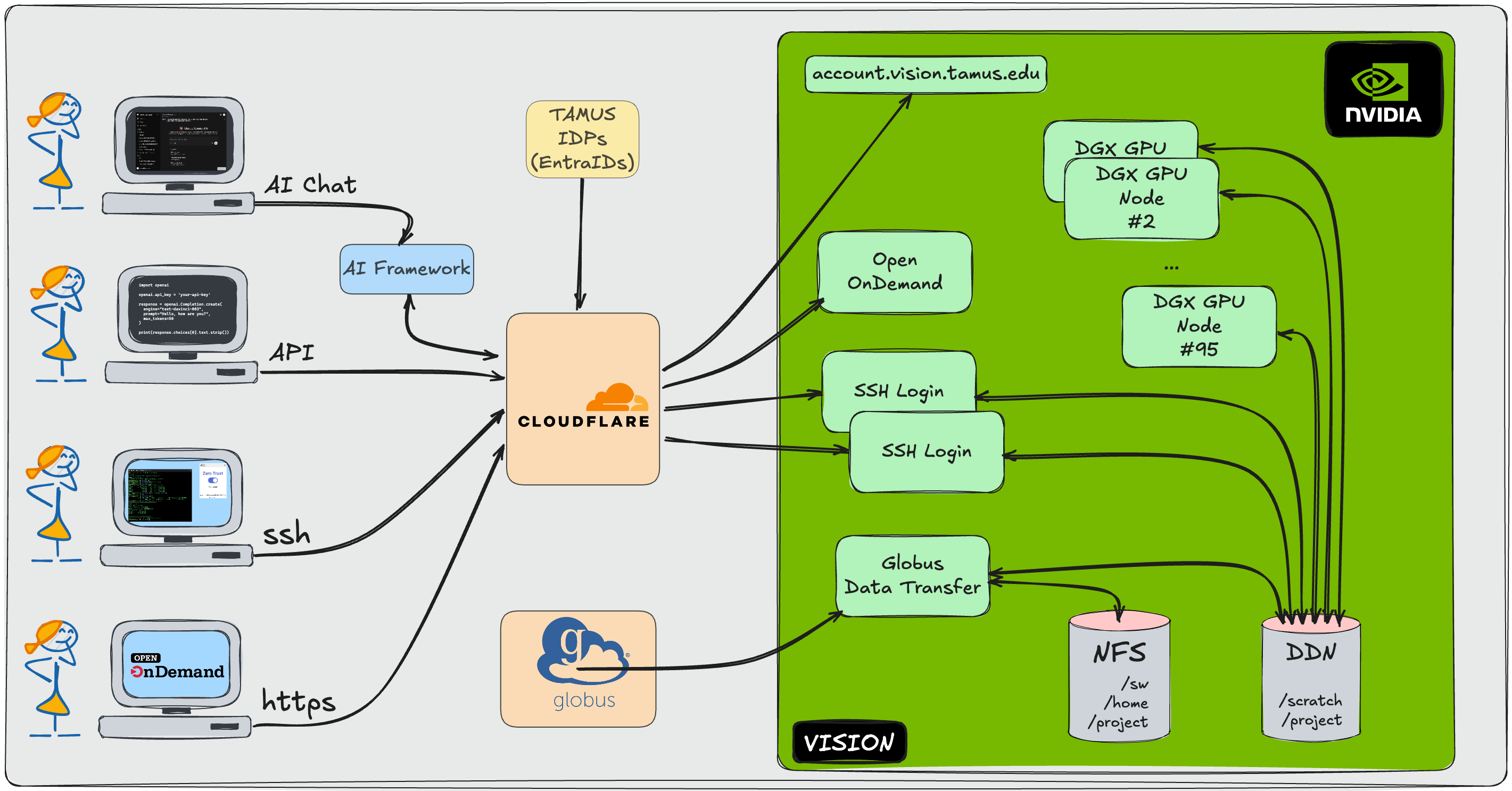
VISION Compute
Each of the 95 NVIDIA DGX nodes has eight NVIDIA H200 Tensor Core GPUs, fourth-generation NVIDIA NVLink, and third-generation NVIDIA NVSwitch™ technologies. Overall, each system has a 1,128 GBs of aggregated HBM3 memory. These nodes are connected together using 4 separate networks (see below).
Usage of these nodes will initially be via Slurm batch jobs via SSH login sessions and the VISION Open OnDemand portal(opens in new window). Small file upload and downloads are also possible via the Open OnDemand portal.
In the relatively near future, access to nodes may be available via Kubernetes as well.
VISION Storage
The VISION supercomputer has several storage systems for use. They are:
- An 8PB Data Direct Networks fast scratch system to support high-throughput, parallel read/write storage services for active, project-based, computational jobs workloads. This storage system is not for long-term file retention and is not backed up. Quotas for this storage will need to be requested and approved based on research project needs. Shared, persistent data sets (e.g. Census data, shared Genomes) will also be supported on this system on a case-by-case basis.
- A 1PB Pure Storage network file system to support long-term storage of user home directories and shared project folders (for code storage, not datasets). Quotas for these are limited to ensure that VISION does not become an archive storage system for research data.
VISION Networking
The VISION supercomputer has 4, separate networks to support compute and operational tasks:
- Compute fabric
- The compute fabric is rail-optimized to the top layer of the fabric.
- The compute fabric is a balanced, full-fat tree.
- Managed NDR switches are used throughout the design to provide better management of the fabric.
- The fabric is designed to support the latest SHaRPv3 features.
- Storage fabric
- It is independent of the compute fabric to maximize performance of both storage and application performance.
- Provides single-node bandwidth of at least 40 GBps to each DGX H200 system.
- Storage is provided over InfiniBand and leverages RDMA to provide maximum performance and minimize CPU overhead.
- It is flexible and can scale to meet specific capacity and bandwidth requirements.
- User-accessible management nodes provide access to shared storage.
- In-band management network
- The in-band management network fabric is Ethernet-based and is used for node provisioning, data movement, Internet access, and other services that must be accessible by the users.
- The in-band management network connections for compute and management servers operate at 100 Gbps and are bonded for resiliency.
- Out-of-band management network
- The OOB management network connects all the base management controller (BMC) ports, as well as other devices and is physically isolated from system users.
VISION Access
In addition to the core, reference architecture components, Texas A&M Technology Services and High Performance Research Computing have collaborated to deploy several services to facilitate use of VISION by all members of the Texas A&M System in a uniform and secure fashion. These services enable login access, data movement, and future Large Language Model (LLM) inference via API calls
Access to VISION is currently only possible via invitation. If you would like to request an invitation, please visit the VISION Access Request Form(opens in new window).
Cloudflare and Cirrus Identity
Cloudflare is the primary access control system for VISION. All remote access to the following services is facilitated by encrypted Cloudflare Tunnels, Cloudflare Access, and the Cloudflare One network overlay system.
Cirrus Identity provides access to the VISION account management portal(opens in new window).
Logging into VISION services via Cloudflare allows System Member researchers and users to utilize their existing campus-specific Entra ID login information to connect.
Cloudflare One uses an endpoint agent to create a secure network overlay. By using this, users can connect to the VISION login nodes using a native, endpoint SSH client.
Login nodes
VISION has two, identical login nodes. These can be accessed using the VISION Cloudflare One client and SSH clients or via the VISION Portal(opens in new window). In the VISION Portal, there is a menu item that will establish an SSH session to one of the login nodes. Note that in the future, after the Cloudflare One client is deployed more widely, access to the VISION Portal will require Cloudflare One.
The two login nodes are also called slogin-01.login.vision.tamus.edu and slogin-02.login.vision.tamus.edu. When a user initiates a connection login.vision.tamus.edu they are routed to one of the login nodes automatically, and consistently, based on a mapping of your login identity. If, for some reason, a user cannot reach one, they can try the other one.
The login nodes are the only direct shell access to VISION, and they provide several key features:
- Access to file services
-
Persistent, long-term, backed-up NFS:
- An individual 10GB home directory (
/home/<vision-login-id>)
- An individual 10GB home directory (
-
Temporary, short-term use, not-backed up Fast Scratch:
- A 1TB user fast scratch directory (
/scratch/user/<vision-login-id>) - One or more shared project directories with varying allocated sizes (
/scratch/project/prj-##-<project-name>)
- A 1TB user fast scratch directory (
-
A message of the day (motd) that displays current quota and usage information:
Your current disk quotas are:
Disk Disk Usage Limit File Usage Limit
/scratch/user/<login-id>_<member-domain> 954M 1.0T 32 1000000000
/scratch/project/prj-02-<project1-name> 52K 10.0T 13 5000000
/scratch/project/prj-02-<project2-name> 17.2G 10.0T 83 5000000
Disk Disk Usage Limit
/home/<login-id>_<member-domain> 1.81 GiB 10.00 GiB -
Access to VISION tools
- compilers
- Slurm commands
- modules and drivers
- specialized software
- general unix utilities
-
The login nodes are not to be used for running any computationally intensive jobs. They are for development and submission of jobs to the VISION compute nodes.
Globus Data Transfer Nodes
The VISION design includes redundant Data Transfer Nodes (DTN)(opens in new window) via Globus Connect Servers(opens in new window). These system DTNs are high-performance, multi-user, parallel-data-stream servers that move data to and from other DTNs. These are typically dedicated servers with specailized hardware for moving massive data quickly over long distances. There are also single-user Globus Connect Personal(opens in new window) software applications that can be used with Globus Connect Servers to move data to and from laptops or desktop workstations.
VISION currently offers one Globus Collection, TAMUS VISION Supercomputer DTN(opens in new window). This Collection provides access to:
- Persistent, long-term, backed-up NFS:
- An individual 10GB home directory (
/home/<vision-login-id>)
- An individual 10GB home directory (
- Temporary, short-term use, not-backed up Fast Scratch:
- A 1TB user fast scratch directory (
/scratch/user/<vision-login-id>) - One or more shared project directories with varying allocated sizes (
/scratch/project/prj-##-<project-name>)
- A 1TB user fast scratch directory (
Documentation on how to use VISION Globus via the web user interface and command-line is also available.
Other Globus enabled services such as Flows(opens in new window), Compute(opens in new window), and Streaming Data(opens in new window) will be developed and activated for VISION. Additionally, the concepts in Research Automation(opens in new window) are worth exploring in support of various research workflows.
Access to the VISION Globus Connect Servers requires a valid Globus account that is authenticated by the users' member institutional identity provider using CILogin. When connecting to VISION, a dynamic mapping is made between the users' home identity (e.g. NetID@tamu.edu) to a VISION identity (e.g. netid_tamu.edu). If the user's home IDP is not yet integrated with CILogin, it may be possible to arrange for a static mapping of a Globus ID until that integration is complete.
Open OnDemand
Along with the command-line access to VISION, users may also use the VISION Open OnDemand Portal(opens in new window). This web interface provides another means by which users can access a VISION login node, copy smaller data files in and out of VISION storage systems, submit Slurm jobs, access interactive applications (coming soon), and monitor various VISION components.
Slurm Workload Manager
Slurm(opens in new window) is the open source, fault-tolerant, and highly scalable cluster management and job scheduling system for VISION. It provides three, core functions[^1] ^1(opens in new window)
- It allocates exclusive and/or non-exclusive access to resources (compute nodes) to users for some duration of time so they can perform work.
- It provides a framework for starting, executing, and monitoring work (normally a parallel job) on the set of allocated nodes.
- It arbitrates contention for resources by managing a queue of pending work.
Configuring Slurm to provide fair use with high-utilization of VISION is very complicated. The configuration will evolve and be optimized frequently during the Alpha and Beta phases of the VISION deployment. After VISION is generally available, the Slurm configuration will continue to change, but this will happen less frequently. Documentation about the Slurm configuration and usage on VISION is available.
Large Language Model Inference (API)
A portion of the VISION compute nodes (3 DGX nodes, each with 8 NVIDIA H200 GPUs) are dedicated to running Kubernetes workloads to support the deployment of open-source and locally-developed Large Language Models (LLMs) for production inference usage by System Members. These models will be available through the TAMUS AI Framework(opens in new window) for use with the TAMUS AI Chat web interface and TAMUS AI API services. OpenAI's gpt-oss(opens in new window) and Google Deepmind's gemma4(opens in new window) models are planned for initial deployment.